Hi, Guset, 您可以 立即注册 Or 登录,还可以 QQ登录
4
6
15
新手上路
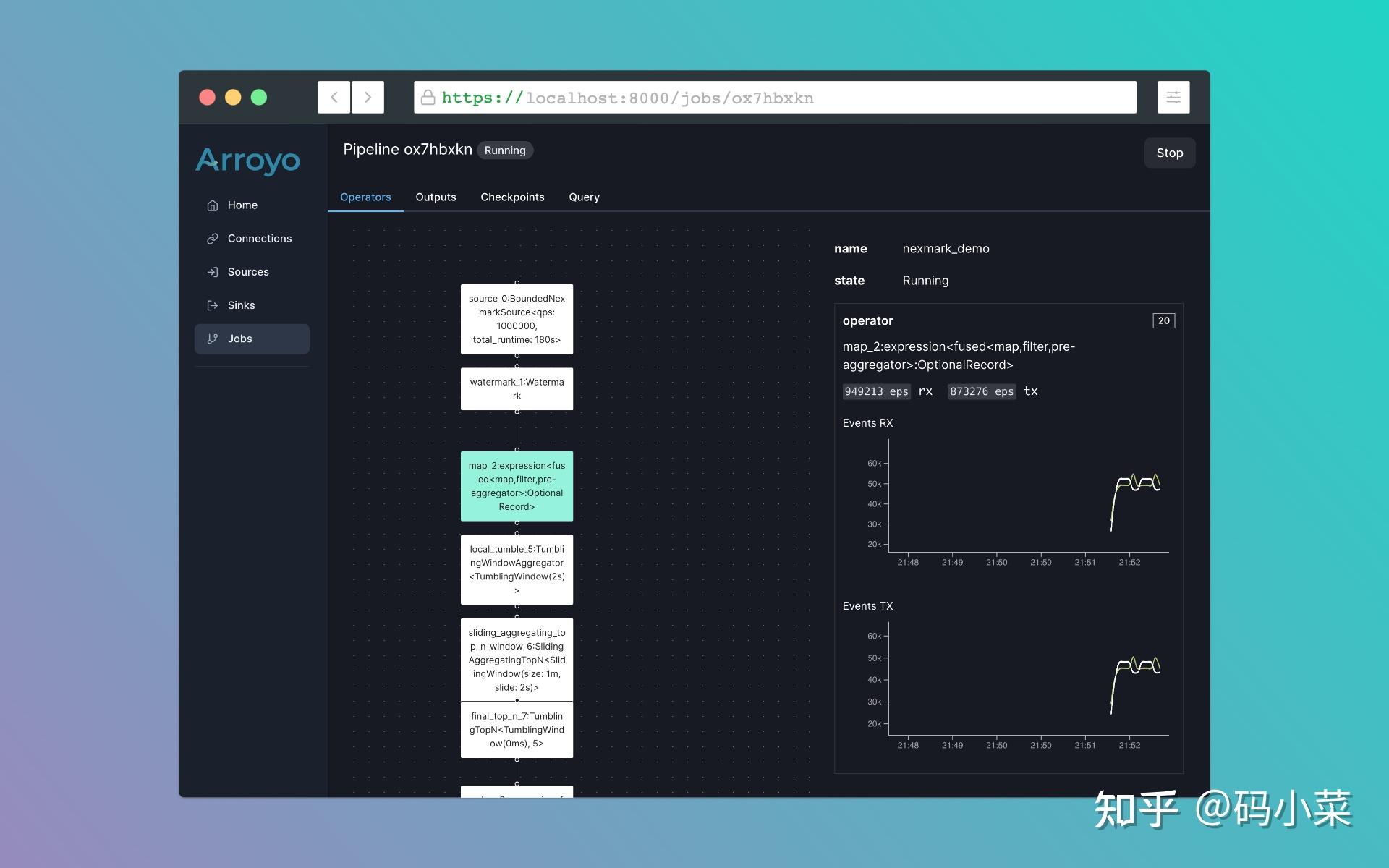
说到这里,感觉就是Flink在Rust中的完美替代品。如果真的可以稳定使用,那么将是Rust撼动Java在大数据流式处理计算的第一枪。
使用道具 举报
0
2
3
1
10
本版积分规则 发表回复 回帖后跳转到最后一页
Archiver|手机版|小黑屋|咸蛋黄
GMT+8, 2025-3-16 07:57 , Processed in 0.096190 second(s), 22 queries .
Powered by Discuz! X3.4. 技术支持 by 巅峰设计
© 2001-2013 Comsenz Inc.
 发表于 2023-4-10 20:30:48
|
显示全部楼层
发表于 2023-4-10 20:30:48
|
显示全部楼层